
 à developpez.com")




I. Préambule▲
OpenERP est une suite moderne de d'Applications Métiers, publiée sous la licence AGPL qui comprend les modules CRM, RH, ventes, comptabilité, fabrication, gestion d'entrepôts, gestion de projets, et plus encore. Il est basé sur un système modulaire, une plate-forme Rapid Application Development (RAD) évolutive et intuitive écrite en Python.
OpenERPdispose d'une boîte à outils complète et modulaire pour construire rapidement des applications : Object-Relationship Mapping (ORM) intégré, un patron Modèle-Vue-Contrôleur (MVC), un système de génération de rapport, l'internationalisation automatisée, et bien plus encore.
Python est un langage de programmation dynamique de haut niveau, idéal pour RAD, alliant la puissance avec une syntaxe claire, et un noyau maintenu petit par sa conception.
- Le site Web principal OpenERP et téléchargements : www.openerp.com
- Documentation fonctionnelle et technique : doc.openerp.comDocumentation OpenERP
- Ressources communautaires :
 www.openerp.com/community
www.openerp.com/community - Le serveur d'intégration permanent : runbot.openerp.comServeur d'integration OpenERP
- Apprendre Python : doc.python.orgDocumentation Python
II. Installer OpenERP▲
OpenERP est distribué sous forme de paquets/installeurs pour la plupart des plates-formes, mais peut également être installé à partir des sources sur n'importe quelle plate-forme.

OpenERP utilise le paradigme client-serveur bien connu : le client s'exécute comme une application JavaScript dans votre navigateur, se connectant au serveur en utilisant le protocole JSON-RPC sur HTTP(S). Des clients peuvent être facilement écrits selon vos besoins et se connecter au serveur en utilisant XML-RPC ou JSON-RPC.
- La procédure d'installation OpenERP est susceptible d'évoluer (dépendances et ainsi de suite), alors assurez-vous de toujours consulter la documentation spécifique (fournie avec les packages et sur le site Internet) pour les dernières procédures.
- Voir : http://doc.openerp.com/v7.0/installInstallation d'OpenERP
II-A. Packages d'installation▲
- Windows : installeur tout-en-un.
- Linux : packages tout-en-un pour les systèmes basés sur Debian (*.deb), et Red-Hat (*.rpm).
- Mac : pas d'installeur tout-en-un, il faut installer depuis les sources.
II-B. Installer depuis les sources▲
Il y a deux possibilités : utiliser une archive fournie sur le site, ou obtenir directement les sources à l'aide de BazaarBazaar (système de contrôle de version). Vous devez également installer les dépendances nécessaires (PostgreSQL et quelques bibliothèques Python - voir la documentation sur doc.openerp.comDocumentation OpenERP).
Astuce : Compilation
OpenERP étant basé sur Python, aucune compilation n'est nécessaire.
2.
3.
4.
$ sudo apt-get install bzr # Installer Bazaar (version control software)
$ bzr cat -d lp:~openerp-dev/openerp-tools/trunk setup.sh | sh # Récupérer l'Installeur
$ make init-v70 # Installer OpenERP 7.0
$ make server # Démarrer OpenERP Server avec l'interface Web
II-C. Création de la base de données▲
Après le démarrage du serveur, ouvrez http://localhost:8069 dans votre navigateur préféré. Vous verrez l'écran du gestionnaire de bases de données où vous pouvez créer une nouvelle base de données. Chaque base de données possède ses propres modules et sa propre configuration, et peut être créée en mode démo pour tester une base de données préremplie (ne pas utiliser le mode de démonstration pour une véritable base de données !).
III. Construire un module OpenERP : Idea (Idée)▲
III-A. Contexte▲
Les exemples de code utilisés dans ce mémento sont pris à partir d'un module hypothétique d'idées. Le but de ce module serait d'aider les esprits créatifs, qui viennent souvent avec des idées qui ne peuvent pas être réalisées immédiatement, et sont trop facilement oubliées si elles ne sont pas notées quelque part. Ce module pourrait être utilisé pour enregistrer ces idées, les trier et les évaluer.
Note : développement modulaire
OpenERP utilise des modules comme des conteneurs de fonctionnalités, afin de favoriser un robuste développement et leur maintenance. Les modules offrent une isolation des fonctions, un niveau approprié d'abstraction et des modèles évidents MVC.
III-B. Composition d'un module▲
Un module peut contenir n'importe lequel des éléments suivants :
- objets métier : déclarés comme des classes Python qui étendent la classe osv.Model. La persistance de ces ressources est entièrement gérée par OpenERP ;
- données : les fichiers XML/CSV avec des métadonnées (vues et déclarations des flux de travail), les données de configuration (paramétrage des modules) et des données de démonstration (facultatives, mais recommandées pour tester, par exemple, des échantillons d'idées) ;
- assistants : formulaires interactifs utilisés pour aider les utilisateurs, souvent disponibles en actions contextuelles sur les ressources ;
- rapports : RML (format XML), MAKO ou OpenOffice modèles de rapports, qui seront fusionnés avec n'importe quel type de données de l'entreprise et généreront du HTML, ODT ou des rapports PDF.
III-C. Structure typique d'un module▲
Chaque module est contenu dans son propre répertoire, dans le répertoire d'installation du serveur server/bin/addons.
Note :
Vous pouvez déclarer votre propre répertoire addons dans le fichier de configuration d'OpenERP en utilisant l'option addons_path (transmis au serveur avec l'option -c).
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
addons/
|- idea/ # Le répertoire du module
|- demo/ # Données de démonstration et tests unitaires
|- i18n/ # Fichiers de traduction
|- report/ # Rapports
|- security/ # Déclaration des groupes et droits d'accès
|- view/ # Vues (formulaires,listes), menus et actions
|- wizard/ # Assistants
|- workflow/ # Flux de travail
|- __init__.py # Fichier d'initialisation Python (requis)
|- __openerp__.py # Déclaration du module (requis)
|- idea.py # Classes Python, les objets du module
Le fichier __ init__.py est le descripteur de module Python, car un module OpenERP est aussi un module Python régulier.
18.
# Importe tous les fichiers et dossiers qui contiennent du code Python
import idea, wizard, report
Le fichier __openerp__.py est le manifeste du module OpenERP et contient un dictionnaire unique Python avec la déclaration du module : son nom, les dépendances, la description et la composition.
20.
21.
22.
23.
24.
25.
26.
27.
28.
29.
30.
31.
32.
33.
34.
35.
36.
{
'name' : 'Idea',
'version' : '1.0',
'author' : 'OpenERP',
'description' : 'Ideas management module',
'category': 'Enterprise Innovation',
'website': 'http://www.openerp.com',
'depends' : ['base'], # liste des dépendances conditionnant l'ordre de démarrage
'data' : [ # les fichiers de données à charger lors de l'installation du module
'security/groups.xml', # toujours charger les groupes en premier!
'security/ir.model.access.csv', # charger les droits d'accès après les groupes
'workflow/workflow.xml',
'view/views.xml',
'wizard/wizard.xml',
'report/report.xml',
],
'demo': ['demo/demo.xml'], # données de démo (pour les tests unitaires)
}
III-D. Service de mappage objet-relationnel▲
Élément-clé d'OpenERP, l'ORM est une couche de mappage objet-relationnel complet, qui permet aux développeurs de ne pas avoir à écrire la plomberie SQL de base. Les objets métiers sont déclarés comme les classes Python qui héritent de la classe osv.Model, ce qui les rend magiquement persistants par la couche ORM.
Des attributs prédéfinis sont utilisés dans la classe Python pour spécifier les caractéristiques d'un objet métier pour l'ORM :
38.
39.
40.
41.
42.
43.
44.
45.
46.
47.
48.
49.
50.
51.
52.
53.
54.
55.
56.
57.
58.
59.
60.
61.
62.
63.
64.
65.
66.
67.
68.
69.
70.
from osv import osv, fields
class idea(osv.Model):
_name = 'idea.idea'
_columns = {
'name': fields.char('Title', size=64, required=True, translate=True),
'state': fields.selection([('draft','Draft'),
('confirmed','Confirmed')],'State',required=True,readonly=True),
# Description est en lecture seule quand elle n est pas en brouillon!
'description': fields.text('Description', readonly=True,
states={'draft': [('readonly', False)]} ),
'active': fields.boolean('Active'),
'invent_date': fields.date('Invent date'),
# par convention, les champs many2one se terminent par '_id'
'inventor_id': fields.many2one('res.partner','Inventor'),
'inventor_country_id': fields.related('inventor_id','country',
readonly=True, type='many2one',
relation='res.country', string='Country'),
# par convention, les champs *2many se terminent par '_ids'
'vote_ids': fields.one2many('idea.vote','idea_id','Votes'),
'sponsor_ids': fields.many2many('res.partner','idea_sponsor_rel',
'idea_id','sponsor_id','Sponsors'),
'score': fields.float('Score',digits=(2,1)),
'category_id' = fields.many2one('idea.category', 'Category'),
}
_defaults = {
'active': True, # les idées sont actives par défaut
'state': 'draft', # les idées sont à l'état de brouillon par défaut
}
def _check_name(self,cr,uid,ids):
for idea in self.browse(cr, uid, ids):
if 'spam' in idea.name: return False # On ne peut pas créer une idée avec spam!
return True
_sql_constraints = [('name_uniq','unique(name)', 'Ideas must be unique!')]
_constraints = [(_check_name, 'Please avoid spam in ideas !', ['name'])]
| Attributs prédéfinis de osv.osv pour les objets métier | |
| _name (requis) | Nom de l'objet métier, en notation pointée (dans le module d'espace de nom) |
| _columns (requis) | Dictionnaire {nom du champ → déclaration du champ} |
| _defaults | Dictionnaire : {nom du champ → littéral ou une fonction fournissant la valeur par défaut} _defaults['name'] = lambda self,cr,uid,context: 'eggs' |
| _auto | Si True (par défaut) l'ORM va créer la table de base de données - Mettre à False pour créer votre propre table/vue dans la méthode init() |
| _inherit | _name : nom de l'objet métier parent (par héritage) |
| _inherits | Pour la décoration de l'héritage : dictionnaire mappant le nom (_name) de l'objet(s) métier parent avec les noms des champs de clé étrangère correspondante à utiliser |
| _constraints | Liste des tuples qui définissent des contraintes Python, sous la forme (func_name, message, champs) (→70) |
| _sql_constraints | Liste des tuples qui définissent des contraintes SQL, sous la forme (nom, sql_def, message) (→69) |
| _log_access | Si True (par défaut), 4 champs (create_uid, create_date, write_uid, write_date) seront utilisés pour identifier les opérations au niveau des enregistrements, accessible via la fonction perm_read() |
| _order | Nom du champ utilisé pour trier les enregistrements dans des listes (par défaut : 'id') |
| _rec_name | Champ alternatif à utiliser comme nom, utilisé par name_get() (par défaut : 'name') |
| _sql | Code SQL pour créer la table/vue de cet objet (si _auto est False) - Peut être remplacé par l'exécution SQL dans la méthode init() |
| _table | Nom de la table SQL à utiliser (par défaut : '.'_name avec des points remplacés par des underscores '_') |

III-E. Types de champs de l'ORM▲
Les objets peuvent contenir trois types de champs : simples, relationnels et fonctionnels.
Les types simples sont des nombres entiers, flottants, booléens, chaînes, etc.
Les champs relationnels représentent les relations entre les objets (one2many, many2one, many2many). Les champs fonctionnels ne sont pas stockés dans la base de données, mais calculés à la volée comme des fonctions Python. Des exemples pertinents dans la classe idea ci-dessus sont indiqués avec les numéros de ligne correspondants (→ XX, XX).
| Types de champs de l'ORM | |
|
|
| Champs simples | |
| boolean (…) integer (…) date (…) datetime (…) time (…) | 'active' : fields.boolean('Active'), 'priority' : fields.integer('Priority'), 'start_date' : fields.date('Start Date'), |
| char(string,size,translate=False…) text(string, translate=False…) Champs de texte |
|
| float(string, digits=None…) Valeur décimale |
|
| selection(values, string…) Champ permettant la sélection entre un ensemble de valeurs prédéfinies |
|
| binary(string, filters=None…) Champ pour stocker un fichier ou du contenu binaire. |
|
| reference(string, selection, size,..) Champ en relation dynamique avec n'importe quel autre objet, associé à un widget assistant |
|
| Champs relationnels | |
| Les attributs communs pris en charge par des champs relationnels | domain : filtre en option sous la forme d'arguments pour la recherche (voir search()) |
| many2one(obj, ondelete='set null'…) (→50) Relation à un objet parent (en utilisant une clé étrangère) |
|
| one2many(obj, field_id…) (→55) Relation virtuelle vers plusieurs objets (inverse de many2one) |
|
| many2many(obj, rel, field1, field2…) (→ 56) Relation bidirectionnelle entre plusieurs objets |
|
| Champs fonctionnels | |
| function(fnct, arg=None, fnct_inv=None, fnct_inv_arg=None, type='float', fnct_search=None, obj=None, store=False, multi=False,…) Champ fonctionnel simulant un champ réel, calculé plutôt que stocké
|
|
| related(f1, f2, ……, type='float', …) Champ raccourci équivalent à la navigation sur des champs reliés
|
|
| property(obj, type='float', view_load=None, group_name=None, …) Attribut dynamique avec des droits d'accès spécifiques
|
|
- one2many ↔ many2one sont symétriques
- many2many ↔ many2many sont symétriques lorsque inversés (inverse field1 et field2 si explicite)
- one2many ↔ many2one + many2one ↔ one2many = many2many
III-E-1. Noms de champs spéciaux/réservés▲
Quelques noms de champs sont réservés avec un comportement prédéfini dans OpenERP. Certains d'entre eux sont créés automatiquement par le système, et dans ce cas tout champ avec ce nom sera ignoré.
| Noms de champs spéciaux/réservés | |
| id | Identificateur système unique pour l'objet |
| name | Champ dont la valeur est utilisée pour afficher l'enregistrement dans les listes, etc. S'il est manquant, mettre _rec_name pour spécifier un autre champ à utiliser |
| active | Basculer la visibilité : les enregistrements avec active défini à False sont masqués par défaut |
| sequence | Définit l'ordre et permet la réorganisation glisser-déposer si visible dans les vues de liste |
| state | Étapes du cycle de vie de l'objet, utilisée par les attributs states |
| parent_id | Définit la structure de tableau sur des enregistrements, et permet l'opérateur de child_of |
| parent_left, parent_right | Utilisé en conjonction avec le signal _parent_store sur l'objet, permet un accès plus rapide à des structures de tableau (voir également section Optimisation Performance) |
|
create_date,
create_uid, write_date, write_uid |
Utilisé pour enregistrer l'utilisateur créateur, l'utilisateur qui a mis à jour, la date de création et la date de dernière mise à jour de l'enregistrement. Désactivée si le signal _log_access est défini sur False (créé par ORM, ne pas les ajouter) |
III-F. Travailler avec l'ORM▲
Héritant de la classe de osv.Model, rend toutes les méthodes de l'ORM disponibles sur des objets métier. Ces méthodes peuvent être appelées sur l'objet lui-même (self) au sein de la classe Python (voir les exemples dans le tableau ci-dessous), ou de l'extérieur de la classe en obtenant d'abord une instance via le système pool de l'ORM.
Exemple d'utilisation de l'ORM
73.
74.
75.
76.
77.
78.
79.
80.
81.
82.
83.
84.
85.
class idea2(osv.Model):
_inherit = 'idea.idea'
def _score_calc(self,cr,uid,ids,field,arg,context=None):
res = {}
# Cette boucle génère seulement deux requêtes grâce à browse()!
for idea in self.browse(cr,uid,ids,context=context):
sum_vote = sum([v.vote for v in idea.vote_ids])
avg_vote = sum_vote/len(idea.vote_ids)
res[idea.id] = avg_vote
return res
_columns = {
# Remplace le score statique avec une moyenne des scores
'score':fields.function(_score_calc,type='float')
}
| Méthodes de l'ORM sur les objets osv.Model | |
| Accesseur générique à OSV |
|
| Les paramètres communs, utilisés par de multiples méthodes |
|
|
search
(cr, uid, domain, offset=0, limit=None, order=None, context=None, count=False)
Renvoie : liste des identifiants des enregistrements correspondant aux critères donnés |
|
|
Sélectionnez |
|
|
create
(cr, uid, values, context=None)
Crée un nouvel enregistrement avec la valeur spécifiée Renvoie : id du nouvel enregistrement |
|
|
Sélectionnez |
|
|
read
(cr, uid, ids, fields=None, context=None)
Renvoie : liste des dictionnaires avec des valeurs de champs demandés |
|
|
Sélectionnez |
|
|
read_group
(cr, uid, domain, fields, groupby, offset=0, limit=None, orderby=None, context=None)
Renvoie : liste des dictionnaires avec des valeurs de champs demandés, regroupés par les champs spécifiés (groupby). |
|
|
Sélectionnez |
|
|
write
(cr, uid, ids, values, context=None)
Met à jour des enregistrements avec les identifiants donnés aux valeurs indiquées. Renvoie : True |
|
|
Sélectionnez |
|
|
copy
(cr, uid, id, defaults,context=None)
Duplique l'enregistrement de l'id donné en le mettant à jour avec des valeurs par défaut. Renvoie : True |
|
|
unlink
(cr, uid, ids, context=None)
Supprime les enregistrements des id spécifiés Renvoie : True |
Sélectionnez |
|
browse
(cr, uid, ids, context=None)
Récupère les enregistrements comme des objets, ce qui permet d'utiliser la notation à point pour parcourir les champs et les relations. Renvoie : objet ou une liste d'objets demandés |
Sélectionnez |
|
default_get
(cr, uid, fields,
context=None) Renvoie : dictionnaire des valeurs par défaut pour les champs (définies sur la classe d'objets, par les préférences d'utilisateur, ou par l'intermédiaire du contexte) |
|
|
Sélectionnez |
|
|
perm_read
(cr, uid, ids, details=True)
Renvoie : une liste de dictionnaires de propriétés pour chaque enregistrement demandé |
|
|
Sélectionnez |
|
|
fields_get
(cr, uid, fields=None, context=None)
Renvoie un dictionnaire de dictionnaires de champs, chacun décrivant un champ de l'objet métier |
|
|
Sélectionnez |
|
| fields_view_get(cr, uid, view_id=None, view_type='form', context=None, toolbar=False) Renvoie un dictionnaire décrivant la composition de la vue demandée (y compris les vues héritées) |
|
|
Sélectionnez |
|
|
name_get
(cr, uid, ids, context=None)
Renvoie des tuples avec la représentation textuelle des objets demandés pour les relations to-many |
Sélectionnez |
|
name_search
(cr, uid, name='', domain=None, operator='ilike', context=None, limit=80)
Renvoie une liste de noms d'objets correspondant aux critères utilisés pour permettre l'achèvement des relations to-many. Équivalent de search() sur le name (nom) + name_get() |
|
|
Sélectionnez |
|
| export_data(cr, uid, ids, fields, context=None) Exportation des champs des objets sélectionnés, renvoyant un dictionnaire avec une matrice de données. Utilisé lors de l'exportation de données via le menu du client. |
|
|
import_data
(cr, uid, fields, data, mode='init', current_module='', noupdate=False, context=None, filename=None)
Importe les données spécifiées dans le module spécifié utilisé lors de l'exportation de données via le menu du client |
|
Astuce :
Utilisez read() pour des appels via des Web services, mais préférez browse() en interne.
IV. Construire l'interface du module▲
Pour construire un module, le mécanisme principal est d'insérer des enregistrements de données pour déclarer les composants de l'interface du module. Chaque élément du module est un bloc de données standard : les menus, les vues, les actions, les rôles, les droits d'accès, etc.
IV-A. Structure XML commune▲
Les fichiers XML déclarés dans la section des données d'un module contiennent des déclarations d'enregistrement sous la forme suivante :
88.
89.
90.
91.
92.
93.
94.
95.
96.
97.
98.
99.
100.
<?xml version="1.0" encoding="utf-8"?>
<openerp>
<data>
<record model="object_model_name" id="object_xml_id">
<field name="field1">value1</field>
<field name="field2">value2</field>
</record>
<record model="object_model_name2" id="object_xml_id2">
<field name="field1" ref="module.object_xml_id"/>
<field name="field2" eval="ref('module.object_xml_id')"/>
</record>
</data>
</openerp>
Chaque type d'enregistrement (vue, menu, action) prend en charge un ensemble spécifique d'entités et d'attributs enfants, mais tous partagent les attributs spéciaux suivants :
| id | l'identificateur externe unique (par module) de cet enregistrement (xml_id) |
| ref | peut être utilisé à la place du contenu normal de l'élément pour se référencer à un autre enregistrement (fonctionne entre les modules en faisant précéder par le nom du module parent) |
| eval | utilisé à la place du contenu d'un élément pour fournir de la valeur comme une expression Python, et qui peut utiliser la méthode ref() pour trouver l'identifiant dans base de données pour un xml_id spécifié |
Astuce : Validation XML RelaxNG
OpenERP valide la syntaxe et la structure des fichiers XML, selon la grammaire RelaxNGPage officielle Relax NG, que l'on peut trouver à :
server/bin/import_xml.rng
Pour une vérification manuelle, utilisez :
xmllint: xmllint -relaxng /path/to/import_xml.rng <file>
IV-B. Syntaxe CSV commune▲
Les fichiers CSV peuvent également être ajoutés dans la section de données et les enregistrements seront insérés par la méthode import_data() de l'OSV, en utilisant le nom du fichier CSV afin de déterminer le modèle de l'objet cible. L'ORM reconnecte automatiquement les relations basées sur les noms des colonnes spéciales suivantes :
| id (xml_id) | colonne contenant des identificateurs pour les relations |
| many2one_field | reconnecte many2one en utilisant name_search() |
| many2one_field:id | reconnecte many2one basé sur le xml_id de l'objet |
| many2one_field.id | reconnecte many2one basé sur l'id de l'objet de base de données |
| many2many_field | reconnecte via name_search(), multiples valeurs séparées par des virgules |
| many2many_field:id | reconnecte les xml_id des objets, multiples valeurs séparées par des virgules |
| many2many_field.id | reconnecte les id des objets de base de données, multiples valeurs séparées par des virgules |
| one2many_field/field | crée un enregistrement one2many de destination et assigne la valeur de champ |
ir.model.access.csv
102.
103.
"id","name","model_id:id","group_id:id","perm_read","perm_write","perm_create","perm_unlink"
"access_idea_idea","idea.idea","model_idea_idea","base.group_user",1,0,0,0
"access_idea_vote","idea.vote","model_idea_vote","base.group_user",1,0,0,0
IV-C. Menus et actions▲
Les actions sont déclarées comme enregistrements réguliers et peuvent être déclenchées de trois façons :
- en cliquant sur les éléments de menu liés à une action spécifique ;
- en cliquant sur les boutons dans les vues, si ceux-ci sont connectés à des actions ;
- comme actions contextuelles sur un objet (visible dans la barre latérale).
IV-C-1. Déclaration d'une action▲
105.
106.
107.
108.
109.
110.
111.
112.
113.
114.
<record model="ir.actions.act_window" id="action_id">
<field name="name">action.name</field>
<field name="view_id" ref="view_id"/>
<field name="domain">[list of 3-tuples (max 250 characters)]</field>
<field name="context">{context dictionary (max 250 characters)}</field>
<field name="res_model">object.model.name</field>
<field name="view_type">form|tree</field>
<field name="view_mode">form,tree,calendar,graph</field>
<field name="target">new</field>
<field name="search_view_id" ref="search_view_id"/>
</record>
| id | identificateur de l'action dans la table ir.actions.act_window doit être unique |
| name | nom de l'action (obligatoire) |
| view_id | vue spécifique pour ouvrir (si manquant, la vue avec la plus haute priorité du type spécifié est utilisée) |
| domain | tuple (voir les paramètres de search()) pour filtrer le contenu de la vue |
| context | dictionnaire de contexte à passer à la vue |
| res_model | modèle d'objet sur lequel la vue à ouvrir est définie |
| view_type | mettre à form pour ouvrir les enregistrements en mode édition, mettre à tree pour une vue hiérarchique uniquement |
| view_mode | si view_type est form, la liste des modes d'affichage autorisés pour voir les enregistrements (form, tree, ...) |
| target | mettre à new pour ouvrir la vue dans une nouvelle fenêtre/pop-up |
| search_view_id | identificateur de la vue de recherche pour remplacer le formulaire de recherche par défaut |
IV-C-2. Déclaration d'un menu▲
L'élément menuitem est un raccourci pour déclarer un enregistrement de ir.ui.menu et le connecte à une action correspondante à un enregistrement de ir.model.data.
116.
<menuitem id="menu_id" parent="parent_menu_id" name="label"
action="action_id" groups="groupname1,groupname2" sequence="10"/>
| id | identificateur du menuitem, doit être unique |
| parent | id externe (xml_id) du menu parent dans la hiérarchie |
| name | étiquette de menu optionnelle (par défaut : nom de l'action) |
| action | identificateur de l'action à exécuter, le cas échéant |
| group | liste des groupes qui peuvent voir ce menu (si manquant, tous les groupes peuvent le voir) |
| sequence | indice entier pour ordonner les menuitems du même parent (10,20,30..) |
V. Vues et héritage▲
Les vues forment une hiérarchie. Plusieurs vues d'un même type peuvent être déclarées sur le même objet, et seront utilisées en fonction de leurs priorités. En déclarant une vue héritée, il est possible d'ajouter/supprimer des fonctions dans une vue.
Déclaration d'une vue générique
118.
119.
120.
121.
122.
123.
124.
125.
126.
<record model="ir.ui.view" id="view_id">
<field name="name">view.name</field>
<field name="model">object_name</field>
<!-- types: tree,form,calendar,search,graph,gantt,kanban -->
<field name="type">form</field>
<field name="priority" eval="16"/>
<field name="arch" type="xml">
<!-- contenu de la vue: <form>, <tree>, <graph>, … -->
</field>
</record>
| name | nom de la vue |
| model | modèle d'objet sur lequel la vue est définie (comme res_model dans les actions) |
| type | form, tree, graph, calendar, search, gantt, kanban |
| priority | priorité de la vue, la plus petite est la plus élevée (par défaut : 16) |
| arch | architecture de la vue, voir différents types de vue ci-dessous |
V-A. Vues formulaires (pour voir/modifier les enregistrements)▲
| Éléments autorisés | Tous (voir les éléments du formulaire ci-dessous) |
128.
129.
130.
131.
132.
133.
134.
135.
136.
137.
138.
139.
140.
141.
142.
143.
144.
145.
146.
147.
148.
149.
150.
151.
152.
153.
154.
155.
156.
157.
158.
<form string="Idea form">
<group col="6" colspan="4">
<group colspan="5" col="6">
<field name="name" colspan="6"/>
<field name="inventor_id"/>
<field name="inventor_country_id" />
<field name="score"/>
</group>
<group colspan="1" col="2">
<field name="active"/><field name="invent_date"/>
</group>
</group>
<notebook colspan="4">
<page string="General">
<separator string="Description"/>
<field colspan="4" name="description" nolabel="1"/>
</page>
<page string="Votes">
<field colspan="4" name="vote_ids" nolabel="1">
<tree>
<field name="partner_id"/>
<field name="vote"/>
</tree>
</field>
</page>
<page string="Sponsors">
<field colspan="4" name="sponsor_ids" nolabel="1"/>
</page>
</notebook>
<field name="state"/>
<button name="do_confirm" string="Confirm" type="object"/>
</form>
Nouveau : l'API de formulaire v7.0
Une nouvelle API de vue formulaire a été introduite dans OpenERP 7.0. Elle peut être activée en ajoutant version="7.0" à l'élément <form>.
Cette nouvelle API de formulaire permet de mélanger le code XHTML arbitraire avec des éléments de formulaire réguliers d'OpenERP.
Il introduit également quelques éléments propres à produire des formulaires plus beaux, comme <sheet>, <header>, <footer>, et un ensemble de classes CSS génériques pour personnaliser l'apparence et le comportement des éléments de formulaire.
Les meilleures pratiques et des exemples pour la nouvelle API de formulaire sont disponibles dans la documentation technique :
http://doc.openerp.com/trunk/developers/server/form-view-guidelines
V-A-1. Les éléments de formulaire▲
Les attributs communs à tous les éléments :
- string : label de l'élément ;
- nolabel : mettre à 1 pour cacher l'étiquette du champ ;
- colspan : nombre de colonnes sur lesquelles le champ doit s'étendre ;
- rowspan : nombre de lignes sur lesquelles le champ doit s'étendre ;
- col: nombre de colonnes que cet élément doit allouer à ses éléments enfants ;
- invisible : mettre à 1 pour cacher cet élément complètement ;
- eval : évaluer ce code Python comme contenu d'un élément (le contenu est une chaîne par défaut) ;
- attrs : carte Python définissant les conditions dynamiques sur ces attributs : readonly, invisible, required, en fonction de tuples de recherche sur d'autres valeurs de champs.
field : widgets automatiques en fonction du type de champ correspondant.
Attributs :
- string : étiquette du champ pour cette vue particulière ;
- nolabel : mettre à 1 pour cacher l'étiquette du champ ;
- required : substitue l'attribut requiered du champ du modèle pour cette vue ;
- readonly : substitue l'attribut readonly du champ du modèle pour cette vue ;
- password : mettre à True pour masquer les caractères entrés dans ce champ ;
- context : code Python déclarant un dictionnaire contextuel ;
- domain : code Python déclarant une liste de tuples pour restreindre les valeurs ;
- on_change : méthode Python à appeler lorsque la valeur du champ est modifiée ;
- groups : liste de groupes (id) séparés par des virgules groupe (id ) qui ont la permission de voir ce champ ;
- widget : possibilités du widget de sélection (url, email , image, float_time , reference , html, progressbar , statusbar , handle, etc.).
properties : widget dynamique montrant toutes les propriétés disponibles (pas d'attribut).
button : widget cliquable associé à des actions.
Attributs :
- type : type de bouton : workflow (par défaut), object ou action ;
- name : signal de workflow, nom de la fonction (sans les parenthèses) ou action à appeler (dépend de type) ;
- confirm : texte du message de confirmation lorsque vous cliquez dessus ;
- states : liste des états séparés par des virgules dans lesquels ce bouton s'affiche.
separator : ligne de séparation horizontale pour structurer les vues, avec étiquette facultative.
newline : espace réservé pour l'achèvement de la ligne actuelle de la vue.
label : légende en texte libre ou une légende dans le formulaire.
group : utilisé pour organiser les champs en groupes avec étiquette facultative (rajoute des cadres).
notebook : les éléments d'un notebook sont des onglets pour des éléments page.
Attributs :
- page
- name : étiquette de l'onglet/page ;
- position : position des onglets dans le notebook (inside, top, bottom, left, right).
V-B. Vues dynamiques▲
En plus de ce qui peut être fait avec les attributs states et attrs, des fonctions peuvent être appelées par des éléments de la vue (via les boutons de type object, ou par les déclencheurs on_change sur les champs) pour obtenir un comportement dynamique.
Ces fonctions peuvent modifier l'interface de la vue en renvoyant une carte Python avec les entrées suivantes :
| value | un dictionnaire de noms de champs et leurs nouvelles valeurs |
| domain | un dictionnaire de noms de champs et les valeurs actualisées du domaine |
| warning | un dictionnaire avec un titre et un message à afficher dans une boîte de dialogue d'avertissement |
V-C. Vues listes et listes d'arborescence hiérarchique▲
Les vues liste qui incluent les éléments field, sont créées avec le type tree, et ont un élément parent <tree>. Elles sont utilisées pour définir des listes plates (modifiables ou non) et les listes hiérarchiques.
| Attributs |
|
| Éléments autorisés |
|
160.
161.
162.
<tree string="Idea Categories" toolbar="1" colors="blue:state==draft">
<field name="name"/>
<field name="state"/>
</tree>
V-D. Vues fiches Kanban▲
Note du traducteur :
Définition Wikipédia de « Kanban » :
Un kanban (カンバン ou 看板, terme japonais signifiant « regarder le tableau »?) est une simple fiche cartonnée que l'on fixe sur les bacs ou les conteneurs de pièces dans une ligne d'assemblage ou une zone de stockage.
Voir Kanban sur Wikipédia : http://fr.wikipedia.org/wiki/KanbanDéfinition de Kanban
Depuis OpenERP 6.1, un nouveau type polyvalent de vue, dans laquelle chaque enregistrement est rendu comme un petit « kanban » (fiche) est apparu. Il supporte le glisser-déposer pour gérer le cycle de vie des fiches kanban basées sur des dimensions configurables. Les vues Kanban sont introduites dans les notes de version d'OpenERP 6.1 et définies en utilisant le langage de templates QWeb, documenté dans la documentation technique :
Voir : http://bit.ly/18usDXt
V-E. Vues calendrier▲
Vues utilisées pour afficher les champs de date comme des événements de calendrier (élément parent : <calendar>)
| Attributs |
|
| Éléments autorisés |
|
164.
165.
<calendar string="Ideas" date_start="invent_date" color="inventor_id">
<field name="name"/>
</calendar>
V-F. Diagrammes de Gantt▲
Diagramme à barres généralement utilisé pour afficher le calendrier du projet (élément parent : <gantt>).
| Attributs |
|
| Éléments autorisés |
|
164.
165.
166.
167.
<gantt string="Ideas" date_start="invent_date" color="inventor_id">
<level object="idea.idea" link="id" domain="[]">
<field name="inventor_id"/>
</level>
</gantt>
V-G. Vues diagrammes (graphes)▲
Vues utilisées pour afficher les tableaux de statistiques (élément parent : <graph>).
Astuce :
Les graphiques sont particulièrement utiles avec des vues personnalisées qui permettent d'extraire des statistiques prêtes à l'emploi.
| Attributs |
|
| Éléments autorisés |
|
172.
173.
174.
<graph string="Total idea score by Inventor" type="bar">
<field name="inventor_id" />
<field name="score" operator="+"/>
</graph>
V-H. Vues de recherche▲
Les vues de recherche personnalisent le panneau de recherche en haut des autres vues.
| Éléments autorisés | field, group, separator, label, search, filter, newline, propriétés :
|
176.
177.
178.
179.
180.
181.
182.
183.
184.
185.
186.
187.
<search string="Search Ideas">
<group col="6" colspan="4">
<filter string="My Ideas"
domain="[('inventor_id','=',uid)]"
help="My own ideas"/>
<field name="name"/>
<field name="description"/>
<field name="inventor_id"/>
<!-- le champ de contexte suivant est juste pour illustration -->
<field name="inventor_country_id" widget="selection"
context="{'inventor_country': self}"/>
</group>
</search>
V-I. Héritage des vues▲
Les vues existantes devraient être modifiables à travers des vues héritées, jamais directement.
Une vue héritée se référence à sa vue parent en utilisant le champ inherit_id, et peut ajouter ou modifier des éléments existants dans la vue par leur référencement ou par des expressions XPath, et en spécifiant la position appropriée.
Astuce :
La référence à XPath peut être trouvée à l'adresse www.w3.org/TR/xpathXPath Reference
| position |
|
189.
190.
191.
192.
193.
194.
195.
196.
197.
198.
<!-- amélioration de la liste des catégories d'idée -->
<record id="idea_category_list2" model="ir.ui.view">
<field name="name">id.category.list2</field>
<field name="model">ir.ui.view</field>
<field name="inherit_id" ref="id_category_list"/>
<field name="arch" type="xml">
<xpath expr="/tree/field[@name='description']" position="after">
<field name="idea_ids" string="Number of ideas"/>
</xpath>
</field>
</record>
VI. Rapports▲
Il existe plusieurs moteurs de rapport dans OpenERP, pour produire des rapports à partir de différentes sources et dans de nombreux formats.

Les expressions spéciales utilisées à l'intérieur des modèles de rapport produisent des données dynamiques et/ou modifient la structure du rapport au moment du rendu.
Des analyseurs de rapport personnalisés peuvent être écrits pour supporter d'autres expressions.
VI-A. Différents formats de rapports▲
| sxw2rml | Modèles OpenOffice 1.0 (.sxw) convertis en RML avec l'outil sxw2rml, puis le RML rendu au format HTML ou PDF |
| rml | Modèles RML rendus directement au format HTML ou PDF |
| xml,xsl:rml | Données XML + feuilles de styles XSL:RML pour générer le RML |
| odt2odt | Modèles OpenOffice (.odt) utilisés pour produire directement des documents OpenOffice (.odt) |
VI-B. Les expressions utilisées dans les modèles de rapport OpenERP▲
| Expressions utilisées dans les modèles de rapport OpenERP | |
| [[ <contenu> ]] | Le contenu à l'intérieur des doubles crochets est évalué comme une expression Python sur la base des expressions suivantes |
Expressions prédéfinies :
|
|
2.
3.
4.
<!-- Ce qui suit crée un enregistrement dans le modèle ir.actions.report.xml -->
<report id="idea_report" string="Print Ideas" model="idea.idea"
name="idea.report" rml="idea/report/idea.rml" >
<!-- Utilisez addons/base_report_designer/wizard/tiny_sxw2rml/tiny_sxw2rml.py pour générer le modèle RML depuis un modèle .sxw -->
| id | identifiant de rapport unique |
| name | nom du rapport (obligatoire) |
| model | modèle d'objet sur lequel le rapport est défini (obligatoire) |
| rml, sxw, xml, xsl | chemin vers les sources de modèles (à partir de addons), selon le rapport |
| auto | mettre à False pour utiliser un interpréteur personnalisé, en contournant report_sxw.rml_parse et en déclarant le rapport comme suit : report_sxw.report_sxw(report_name, object_model,rml_path,parser=customClass) |
| header | mettre à False pour supprimer l'en-tête du rapport (par défaut : True) |
| groups | liste de groupes, séparés par des virgules, autorisés à voir ce rapport |
| menu | mettre à True pour afficher le rapport dans le menu d'impression (par défaut : True) |
| keywords | précise le type de mot-clé du rapport (par défaut : client_print_multi) |
Astuce :
Le guide de l'utilisateur RML: www.reportlab.com/docs/rml2pdf-userguide.pdfGuide d'utilisateur de RML
205.
206.
207.
208.
209.
210.
211.
212.
213.
214.
215.
<story>
<blockTable style="Table">
<tr>
<td><para style="Title">Idea name</para> </td>
<td><para style="Title">Score</para> </td>
</tr>
<tr>
<td><para>[[ repeatIn(objects,'o','tr') ]] [[ o.name ]]</para></td>
<td><para>[[ o.score ]]</para></td>
</tr>
</blockTable>
</story>
VII. Les Flux de travail (Workflows)▲
Les flux de travail peuvent être associés à n'importe quel objet dans OpenERP, et sont entièrement personnalisables.
Les flux de travail sont utilisés pour structurer et gérer les cycles de vie des objets et documents commerciaux, et pour définir des transitions, des déclencheurs, etc. avec des outils graphiques.
Les flux de travail, les activités (nœuds ou les actions) et les transitions (conditions) sont déclarés comme des enregistrements XML, comme d'habitude. Les jetons qui naviguent dans les workflows sont appelés workitems.
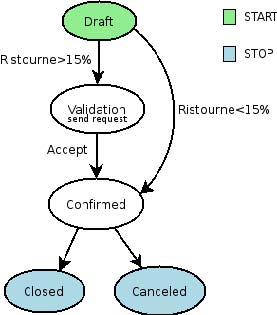
VII-A. Déclaration d'un flux de travail▲
Les flux de travail sont déclarés sur des objets qui possèdent un champ d'état (voir l'exemple de la classe idea dans la section ORM).
217.
218.
219.
220.
<record id="wkf_idea" model="workflow">
<field name="name">idea.basic</field>
<field name="osv">idea.idea</field>
<field name="on_create" eval="1"/>
</record>
| id | identificateur unique d'enregistrement du flux de travail |
| name | nom du flux de travail (obligatoire) |
| osv | modèle d'objet sur lequel le flux de travail est défini (obligatoire) |
| on_create | si True, un élément de travail est instancié automatiquement pour chaque nouvel enregistrement osv |
VII-B. Activités du flux de travail (nœuds)▲
222.
223.
224.
225.
226.
<record id="act_confirmed" model="workflow.activity">
<field name="name">confirmed</field>
<field name="wkf_id" ref="wkf_idea"/>
<field name="kind">function</field>
<field name="action">action_confirmed()</field>
</record>
| id | identificateur unique de l'activité |
| wkf_id | identificateur du flux de travail parent |
| name | étiquette du nœud de l'activité |
| flow_start | True pour faire un nœud 'begin', recevant un workitem (élément de travail pour chaque instance de workflow (flux d'activité) |
| flow_stop | True pour faire un nœud 'end', terminant le flux de travail lorsque tous les éléments l'ont atteint |
| join_mode | comportement logique de ce nœud en ce qui concerne les transitions entrantes :
|
| split_mode | comportement logique de ce nœud en ce qui concerne les transitions sortantes :
|
| kind | type de l'action à exécuter lorsque le nœud est activé par une transition :
|
| subflow_id | en cas de sous-flux, id du sublow à exécuter (utiliser l'attribut ref ou search avec un tuple) |
| action | appel à la méthode de l'objet, utilisé si kind est function ou subflow. Cette fonction doit également mettre à jour le champ d'état de l'objet, par exemple pour un type de fonction : Sélectionnez 1. 2. 3. 4. |
VII-C. Transitions du flux de travail (bords)▲
Les conditions sont évaluées dans cet ordre : role_id, signal, condition, expression
228.
229.
230.
231.
232.
233.
<record id="trans_idea_draft_confirmed" model="workflow.transition">
<field name="act_from" ref="act_draft"/>
<field name="act_to" ref="act_confirmed"/>
<field name="signal">button_confirm</field>
<field name="role_id" ref="idea_manager"/>
<field name="condition">1 == 1</field>
</record>
| act_from, act_to | identifiants des activités de source et de destination |
| signal | nom d'un bouton de type workflow qui déclenche cette transition |
| role_id | référence au rôle que l'utilisateur doit avoir pour déclencher la transition (voir Rôles) |
| condition | expression Python qui doit évaluer la valeur True pour que la transition soit déclenchée |
Astuce :
OpenERP dispose d'un éditeur de flux de travail graphique, disponible en passant à la vue diagramme tout en affichant un flux de travail dans :
Paramètres > Technique > Workflows.
VIII. Sécurité▲
Des mécanismes de contrôle d'accès doivent être combinés pour aboutir à une politique de sécurité cohérente.
VIII-A. Mécanismes de contrôle d'accès basés sur le groupe▲
Les groupes sont créés comme des enregistrements normaux sur le modèle res.groups, et bénéficient d'accès aux menus par des définitions de menu.
Cependant, même sans menu, les objets peuvent encore être accessibles indirectement, donc les autorisations actuelles au niveau de l'objet (create,read,write,unlink) doivent être définies pour les groupes.
Elles sont généralement insérées via des fichiers CSV à l'intérieur des modules. Il est également possible de restreindre l'accès à des champs spécifiques sur une vue ou sur un objet en utilisant l'attribut groups du champ.
235.
236.
"id","name","model_id:id","group_id:id","perm_read","perm_write","perm_create","perm_unlink"
"access_idea_idea","idea.idea","model_idea_idea","base.group_user",1,1,1,0
"access_idea_vote","idea.vote","model_idea_vote","base.group_user",1,1,1,0
VIII-B. Roles▲
Les rôles sont créés comme des enregistrements normaux sur le modèle res.roles et sont utilisés uniquement pour conditionner les transitions de workflow à travers l'attribut role_id des transitions.
IX. Les assistants (Wizards)▲
Les assistants décrivent des sessions d'états interactifs avec l'utilisateur à travers des formulaires dynamiques. Ils sont construits sur la base de la classe osv.TransientModel et sont automatiquement détruits après usage. Ils sont définis en utilisant la même API et les vues sont des objets osv.Model réguliers.
IX-A. Les modèles d'assistant (TransientModel)▲
238.
239.
240.
241.
242.
243.
244.
245.
246.
247.
248.
249.
250.
251.
252.
253.
from osv import fields,osv
import datetime
class cleanup_wizard(osv.TransientModel):
_name = 'idea.cleanup.wizard'
_columns = {
'idea_age': fields.integer('Age (in days)'),
}
def cleanup(self,cr,uid,ids,context=None):
idea_obj = self.pool.get('idea.idea')
for wiz in self.browse(cr,uid,ids):
if wiz.idea_age <= 3:
raise osv.except_osv('UserError','Please select a larger age')
limit = datetime.date.today()-datetime.timedelta(days=wiz.idea_age)
ids_to_del = idea_obj.search(cr,uid, [('create_date', '<' ,
limit.strftime('%Y-%m-%d 00:00:00'))],context=context)
idea_obj.unlink(cr,uid,ids_to_del)
return {}
IX-B. Vues assistant▲
Les assistants utilisent des vues régulières et leurs boutons peuvent utiliser un attribut spécial cancel pour fermer la fenêtre de l'assistant lorsque vous cliquez dessus.
255.
256.
257.
258.
259.
260.
261.
262.
263.
264.
265.
266.
267.
268.
<record id="wizard_idea_cleanup" model="ir.ui.view">
<field name="name">idea.cleanup.wizard.form</field>
<field name="model">idea.cleanup.wizard</field>
<field name="type">form</field>
<field name="arch" type="xml">
<form string="Idea Cleanup Wizard">
<label colspan="4" string="Select the age of ideas to cleanup"/>
<field name="idea_age" string="Age (days)"/>
<group colspan="4">
<button string="Cancel" special="cancel"/>
<button string="Cleanup" name="cleanup" type="object"/>
</group>
</form>
</field>
</record>
IX-C. Exécution de l'assistant▲
Ces assistants sont lancés via les enregistrements d'action réguliers, avec un champ cible spécial utilisé pour ouvrir la vue de l'assistant dans une nouvelle fenêtre.
270.
271.
272.
273.
274.
275.
276.
<record id="action_idea_cleanup_wizard" model="ir.actions.act_window">
<field name="name">Cleanup</field>
<field name="type">ir.actions.act_window</field>
<field name="res_model">idea.cleanup.wizard</field>
<field name="view_type">form</field>
<field name="view_mode">form</field>
<field name="target">new</field>
</record>
X. WebServices - XML-RPC▲
OpenERP est accessible à travers des interfaces XML-RPC, pour lesquels les bibliothèques existent dans de nombreux langages.
278.
279.
280.
281.
282.
283.
284.
285.
286.
287.
288.
289.
290.
291.
import xmlrpclib
# ... definir HOST, PORT, DB, USER, PASS
url = 'http://%s:%d/xmlrpc/common' % (HOST,PORT)
sock = xmlrpclib.ServerProxy(url)
uid = sock.login(DB,USER,PASS)
print "Logged in as %s (uid:%d)" % (USER,uid)
# Crée une nouvelle idée
url = 'http://%s:%d/xmlrpc/object' % (HOST,PORT)
sock = xmlrpclib.ServerProxy(url)
args = {
'name' : 'Another idea',
'description' : 'This is another idea of mine',
'inventor_id': uid,
}
idea_id = sock.execute(DB,uid,PASS,'idea.idea','create',args)
294.
295.
296.
297.
298.
299.
300.
301.
302.
303.
304.
305.
306.
307.
308.
309.
<?
include('xmlrpc.inc'); // Use phpxmlrpc library, available on sourceforge
// ... definir $HOST, $PORT, $DB, $USER, $PASS
$client = new xmlrpc_client("http://$HOST:$PORT/xmlrpc/common");
$msg = new xmlrpcmsg("login");
$msg->addParam(new xmlrpcval($DB, "string"));
$msg->addParam(new xmlrpcval($USER, "string"));
$msg->addParam(new xmlrpcval($PASS, "string"));
resp = $client->send($msg);
uid = $resp->value()->scalarval()
echo "Logged in as $USER (uid:$uid)"
// Crée une nouvelle idée
$arrayVal = array(
'name'=>new xmlrpcval("Another Idea", "string") ,
'description'=>new xmlrpcval("This is another idea of mine" , "string"),
'inventor_id'=>new xmlrpcval($uid, "int"),
);
Note du traducteur :
Il semblerait que l'exemple PHP ne soit pas complet. Il n'est fait mention nulle part du modèle idea.idea, donc le code ci-dessus ne devrait pas pouvoir utiliser la table.
XI. Optimisation des performances▲
En tant que logiciel de gestion d'entreprise qui a généralement à faire face à de grandes quantités d'enregistrements, vous voudriez peut-être faire attention aux conseils suivants, pour obtenir des performances constantes :
- ne placez pas d'appels à browse() à l'intérieur des boucles, mettez-les avant et n'accédez qu'aux objets parcourus à l'intérieur de la boucle. L'ORM optimisera le nombre de requêtes de base de données basé sur les attributs parcourus ;
- évitez la récursivité sur les hiérarchies des objets (objets avec une relation parent_id), en ajoutant des champs d'entiers parent_left et parent_right sur votre objet, et en mettant _parent_store sur True dans votre classe d'objets. L'ORM va utiliser une hiérarchie de précommande transversale modifiée pour être en mesure d'effectuer des opérations récursives (par exemple child_of) avec des requêtes de base de données en temps( 1) au lieu de temps( n) ;
- ne pas utiliser les champs de fonction à la légère, surtout si vous les incluez dans la vue liste.
Pour optimiser les fonctions des champs, deux mécanismes sont disponibles :
multi : tous les champs partageant la même valeur d'attribut multi seront calculés avec un seul appel à la fonction, ce qui devrait alors retourner un dictionnaire des valeurs dans son plan de valeurs,
store : les champs de fonction avec un attribut store seront stockés dans la base de données et recalculés à la demande lorsque les objets de déclenchement applicables sont modifiés. Le format de la spécification de déclenchement est le suivant :
store = {'model': (_ref_fnct, fields, priority)} (voir l'exemple ci-dessous)
312.
313.
314.
315.
316.
317.
318.
319.
320.
321.
322.
323.
324.
325.
326.
327.
328.
329.
330.
331.
332.
333.
def _get_idea_from_vote(self,cr,uid,ids,context=None):
res = {}
vote_ids = self.pool.get('idea.vote').browse(cr,uid,ids,context=context)
for v in vote_ids:
res[v.idea_id.id] = True # Store the idea identifiers in a set
return res.keys()
def _compute(self,cr,uid,ids,field_name,arg,context=None):
res = {}
for idea in self.browse(cr,uid,ids,context=context):
vote_num = len(idea.vote_ids)
vote_sum = sum([v.vote for v in idea.vote_ids])
res[idea.id] = {
'vote_sum': vote_sum,
'vote_avg': (vote_sum/vote_num) if vote_num else 0.0,
}
return res
_columns = {
# Ces champs sont recalculés à chaque fois que l'un des votes change
'vote_avg': fields.function(_compute, string='Votes Average',
store = {'idea.vote': (_get_idea_from_vote,['vote'],10)},multi='votes'),
'vote_sum': fields.function(_compute, string='Votes Sum',
store = {'idea.vote': (_get_idea_from_vote,['vote'],10)},multi='votes'),
}
XII. Communauté/contribution▲
Les projets OpenERP sont hébergés sur Launchpad (LP), où toutes les ressources du projet peuvent être trouvées : les branches Bazaar, suivi des bogues, des plans, des FAQ, etc.
Créez un compte gratuit sur launchpad.net pour être en mesure de contribuer.
| Les groupes Launchpad | ||
| Groupes * | Membres | Restrictions Bazaar/Launchpad |
| OpenERP Quality Team (~openerp) | OpenERP Core Team | Peut fusionner et intégrer sur des branches officielles |
| OpenERP Drivers (~openerp-drivers) | Membres actifs de la communauté sélectionnés | Peut confirmer des bogues et poser des jalons sur les bogues |
| OpenERP Community (~openerp-community) | Groupe ouvert, n'importe qui peut se joindre | Possibilité de créer des branches communautaires où chacun peut contribuer |
*Les membres des groupes supérieurs sont également membres des groupes inférieurs
XIII. Licence▲
Copyright © 2010-2013 Open Object Press. Tous droits réservés.
Vous pouvez récupérer une copie électronique de ce travail et le distribuer si vous ne modifiez pas le contenu. Vous pouvez également imprimer une copie pour être lue par vous seul.
Nous avons des contrats avec différents éditeurs de différents pays pour vendre et distribuer des versions papier ou électroniques de ce travail (traduites ou non) dans les librairies. Cela permet de distribuer et de promouvoir le produit OpenERP. Il nous aide aussi à créer des incitations pour payer les contributeurs et auteurs avec les redevances.
Pour cette raison, l'accord de traduire, modifier ou vendre ce travail est strictement interdit, sauf si OpenERP S.A. (représentant Open Object Press) vous donne une autorisation écrite pour cela.
Bien que toutes les précautions aient été prises dans la préparation de cet ouvrage, l'éditeur et les auteurs n'assument aucune responsabilité pour les erreurs ou omissions, ou pour les dommages résultant de l'utilisation de l'information contenue dans ce document.
Publié par Open Object Press, Grand-Rosière, Belgique.
XIV. Remerciements▲
Remerciements spéciaux à l'équipe d'OpenERP (OpenERP SA) pour avoir permis la traduction et la publication de cet article.
Le site officiel OpenERP : http://www.openerp.com/http://www.openerp.com/
Un grand Merci aux membres de l'équipe de la rédaction de Developpez.com pour leurs conseils et corrections